* denotes equal contribution
Method
Neural motion fields in dynamic 3D Gaussian Splatting (3DGS) enable highly detailed reconstructions, but per-Gaussian neural inference at every frame limits real-time performance. Speedy Deformable 3D Gaussian Splatting (SpeeDe3DGS) bridges this efficiency–fidelity gap through three complementary modules that jointly reduce redundant inference, stabilize temporal consistency, and distill neural motion into compact rigid representations:
- Temporal Sensitivity Pruning (TSP) removes redundant Gaussians by aggregating their gradient sensitivity across both space and time.
- Temporal Sensitivity Sampling (TSS) enhances pruning stability by perturbing timestamps during sensitivity estimation, suppressing floaters and improving temporal coherence.
- GroupFlow clusters Gaussians with similar motion trajectories, replacing per-Gaussian deformations with shared groupwise SE(3) transformations.
Implemented on top of Deformable 3D Gaussians, SpeeDe3DGS reduces redundant primitives, stabilizes temporal pruning, and lowers deformation cost — achieving neural-field fidelity at rendering speeds comparable to non-neural motion models.
Temporal Sensitivity Pruning
For each Gaussian \(\mathcal{G}_i\), we calculate a Temporal Sensitivity Pruning (TSP) score \(\tilde{U}_{\mathcal{G}_i}\), which approximates its second-order sensitivity to the \(L_2\) loss across all training views: \[ \tilde{U}_{\mathcal{G}_i} \approx \nabla_{g_i}^2 L_2 \approx \sum_{\phi, t \in \mathcal{P}_{gt}} \left( \nabla_{g_i} I_{\mathcal{G}_t}(\phi) \right)^2, \] where \(g_i\) is the value of \(\mathcal{G}_i\) projected onto image space, \(\mathcal{P}_{gt}\) denotes the set of training poses and timesteps, and \(I_{\mathcal{G}_t}(\phi)\) is the rendered image at pose \(\phi\) and timestep \(t\).
Since deformation updates vary acrosss timesteps, these gradients are inherently time-dependent and capture the second-order effects of each Gaussian and its deformations on the dynamic scene reconstruction. As such, \(\tilde{U}_{\mathcal{G}_i}\) reflects each Gaussian's cumulative contribution to the scene reconstruction over time. We periodically prune low-contributing Gaussians during training, thereby reducing the neural inference load and boosting rendering speed.
Temporal Sensitivity Sampling
While TSP identifies redundant Gaussians, it relies on gradients from discrete training frames. This may overlook floaters — unstable Gaussians that appear static in observed views but drift at unseen timestamps. To address this, Temporal Sensitivity Sampling (TSS) introduces temporal perturbation during sensitivity estimation by jittering the timestamp input to the deformation field:
\[ (\mu + \Delta\mu, r + \Delta r, s + \Delta s) = \mathcal{D}(\mu, r, s, t + \mathcal{N}(0,1)\beta\Delta t(1 - i/\tau)) \]
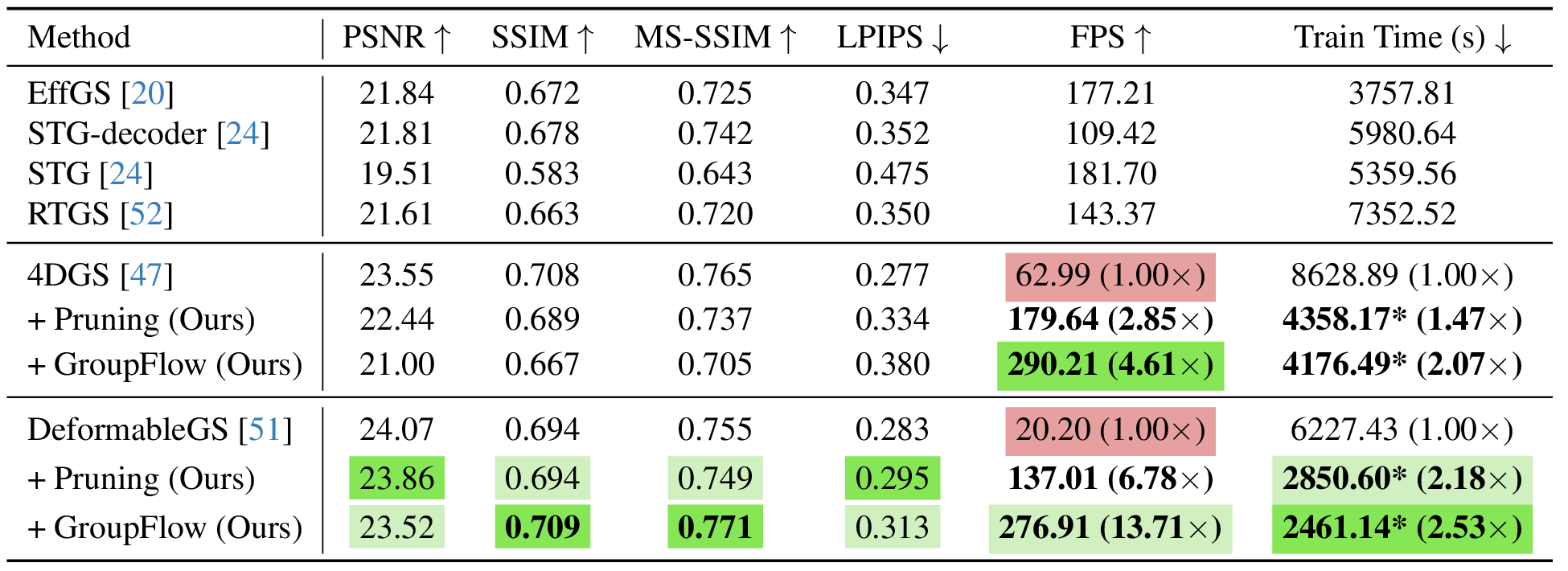
This temporally jittered sampling reveals unstable primitives early in training, encouraging robust pruning and suppressing floaters. The noise magnitude decays linearly (annealing), ensuring precise reconstruction in later stages. Together, TSP and TSS improve temporal smoothness and enable up to 11× fewer Gaussians with comparable image quality to the unpruned baseline.
GroupFlow

Even after pruning, dynamic 3D Gaussian Splatting requires predicting a deformation for every Gaussian, which remains computationally expensive. GroupFlow addresses this by distilling the learned neural motion field into grouped SE(3) transformations that capture locally coherent motion.
Given a dense deformable 3DGS model, each Gaussian \(\mathcal{G}_i\) is represented as a sequence of mean positions \(\mathcal{M}_i = \{\mu_i^t\}_{t=0}^{F-1}\) across \(F\) timesteps. We initialize \(J\) control trajectories \(\{h_j^t\}\) via farthest point sampling at \(t=0\), and assign each \(\mu_i\) to the most similar \(h_j\) using trajectory similarity score:
$$ S_{i,j} = \lambda_r \, \mathrm{std}_t(\| \mu_i^t - h_j^t \|) + (1-\lambda_r) \, \mathrm{mean}_t(\| \mu_i^t - h_j^t \|). $$
We then fit a group-wise SE(3) trajectory to each group \(\mathcal{M}^j\) by aligning sampled means over time. To predict the deformation of \(\mu_i \in \mathcal{M}^j\) at timestep \(t\), we apply a learned SE(3) transformation relative to its control point:
$$ \mu_i^t = R_j^t (\mu_i^0 - h_j^0) + h_j^0 + T_j^t. $$
The shared flow parameters \(\{h_j^0, R_j^t, T_j^t\}\) are optimized jointly with the scene. This formulation distills dense, per-Gaussian neural deformations into a smaller set of groupwise SE(3) motions, reducing the number of transformations per frame from \(N\) (per Gaussian) to \(J\) (per group).
As a result, GroupFlow achieves substantial acceleration during both training and rendering while maintaining temporally coherent, high-quality motion reconstruction. Beyond efficiency, this distillation regularizes the learned motion field, smoothing noisy trajectories and improving robustness in real-world dynamic scenes.
Results
Videos produced using our SpeeDe3DGS codebase.
BibTeX
@article{TuYing2025SpeeDe3DGS,
author = {Tu, Allen and Ying, Haiyang and Hanson, Alex and Lee, Yonghan and Goldstein, Tom and Zwicker, Matthias},
title = {SpeeDe3DGS: Speedy Deformable 3D Gaussian Splatting with Temporal Pruning and Motion Grouping},
journal = {arXiv preprint arXiv:2506.07917},
year = {2025},
url = {https://speede3dgs.github.io/}
}Related Work
For additional papers on efficient 3D Gaussian Splatting, see our group’s related work below. If your research builds on ours, we encourage you to cite these papers.
- Speedy-Splat (CVPR 2025) [BibTeX] — Accelerate 3D Gaussian Splatting rendering speed by over 6× and reduce model size by over 90% through accurately localizing primitives during rasterization and pruning the scene during training, providing a significantly higher speedup than existing techniques while maintaining competitive image quality.
- PUP-3DGS (CVPR 2025) [BibTeX] — Prune 90% of primitives from any pretrained 3D Gaussian Splatting model using a mathematically principled sensitivity score, more than tripling rendering speed while retaining more salient foreground information and higher visual fidelity than previous techniques at a substantially higher compression ratio.